
- 000 开篇词 卓越的团队,必然有一个卓越的领导者.md
- 001 你的能力模型决定你的职位.md
- 002 七位CTO纵论技术领导者核心能力.md
- 003 CEO实话实说:我需要这样的CTO.md
- 004 技术领导者不等于技术管理者.md
- 005 CTO的三重境界.md
- 006 像CEO一样思考.md
- 007 要制定技术战略,先看清局面.md
- 008 技术领导力就是成事的能力.md
- 009 CTO是商业思维和技术思维交汇的那个点.md
- 010 创业公司CTO的认知升级.md
- 011 最合适的技术才是最有价值的技术.md
- 012 谈谈CTO在商业战略中的定位.md
- 013 把脉高效执行的关键要素.md
- 014 从零开始搭建轻量级研发团队.md
- 015 定制高效研发流程.md
- 016 培养中层团队的管理认知.md
- 017 团队成长要靠技巧和体系.md
- 018 做到这四点,团队必定飞速成长.md
- 019 将企业打造成一所终身大学.md
- 020 论团队管理与共同升级.md
- 021 绩效管理的目标不仅仅是绩效考核.md
- 022 验证研发团队价值的绩效考核机制.md
- 023 产品技术团队OKR使用法则.md
- 024 996、987,程序员加班文化你怎么看?.md
- 025 建立有效的员工淘汰机制.md
- 026 让细节的病毒感染你的团队.md
- 027 如何在不同组织文化下推行技术管理.md
- 028 业务高速增长期的团队管理:知轻重、重绸缪、调缓急.md
- 029 被8成的人误解的工程师文化.md
- 030 关于工程师文化的六个问题.md
- 031 五位技术领导者的文化构建实战.md
- 032 文化是管理的那只无形之手.md
- 033 选对的人,做正确的事情.md
- 034 打好技术团队搭建的基础.md
- 035 做个合格的技术岗位面试官.md
- 036 高潜力人才的内部培养.md
- 037 技术创业该如何选择赛道.md
- 038 CTO要掌握的产品哲学:理性与人性的权衡.md
- 039 从客户价值谈技术创新.md
- 040 技术人投身创业公司之前,应当考虑些什么?.md
- 041 技术人创业前要问自己的六个问题.md
- 042 团队激励之分配好你的奖金.md
- 043 通过积分考核提升技术团队的绩效.md
- 044 空降技术高管的择业七计.md
- 045 选好人生下一站--CTO空降上篇.md
- 046 走出至暗时刻--CTO空降下篇.md
- 047 空降领导者平稳落地要做的四道题(上).md
- 048 空降领导者平稳落地要做的四道题(下).md
- 049 打造高效的研发组织架构:高效研发流程那些事(一).md
- 050 你的研发流程符合你的组织架构吗?谈高效研发流程那些事(二).md
- 051 聊聊研发流程管理中的那些坑:高效研发流程那些事(三).md
- 052 数据如何驱动研发高效运转?谈高效研发流程那些事(四).md
- 053 如何打造高效且敏捷的组织文化?谈高效研发流程那些亊(五).md
- 054 打造高速运转的迭代机器:现代研发流程体系打造(一).md
- 055 用机器打造迭代机器:现代研发流程体系打造(二).md
- 056 有了敏捷开发,那交付期限去哪儿了?.md
- 057 敏捷中的期限之殇,软件业该怎么做?.md
- 058 如何打造个人技术品牌?.md
- 059 技术演,有章可循.md
- 060 正确对待技术演中的失误.md
- 061 刘俊强:技术最高决策者应该关注技术细节吗 .md
- 062 张溪梦:技术领袖需要具备的商业价值思维.md
- 063 未来组织形态带来的领导力挑战.md
- 064 如何判断业务价值的高低.md
- 065 如何打造高效的分布式团队?.md
- 066 如何打造有活力、持续创新的研发团队?.md
- 067 如何打造独属自己的工程师文化?.md
- 068 如何打造一个自组织团队?.md
- 069 茹炳晟:QE团队向工程效能团队转型的实践之路.md
- 070 技术、产品、管理的不同视角.md
- 071 什么样的人适合考虑管理角色.md
- 072 创业公司如何招到合适的人才.md
- 073 用数据来分析管理员工.md
- 074 为什么给了高工资,依然留不住核心员工?.md
- 075 刘俊强:一本正经教你如何毁掉一场技术演.md
- 076 内部技术会议的价值.md
- 079 程军:从0到1打造高效技术团队的方法论.md
- 080 技术Leader的持续成长.md
- 081 游舒帆:一流团队必备的商业思维能力.md
- 082 游舒帆:数据力,透过数据掌握公司经营大小事.md
- 083 游舒帆:运营力,让用户出现你期待的行为.md
- 084 游舒帆:策略力,让目标与行动具备高度一致性.md
- 085 游舒帆:敏捷力,拥抱不确定性,与VUCA共舞.md
- 086 刘俊强:管理者必备的高效会议指南(上).md
- 087 刘俊强:管理者必备的高效会议指南(下).md
- 088 刘俊强:做好一对一沟通的关键要素(上).md
- 089 刘俊强:做好一对一沟通的关键要素(下).md
- 090 程军:打造高效技术团队之招人.md
- 091 程军:打造高效技术团队之做事.md
- 092 成敏:技术负责人如何做优先级决策.md
- 093 兰军:团队研发效率低下的要因分析.md
- 094 兰军:提升产品团队研发效率的实践(上).md
- 095 兰军:提升产品团队研发效率的实践(下).md
- 096 阿禅:工程师转型产品经理可能踩到的坑.md
- 097 阿禅:工程师转型产品经理的必备思维.md
- 098 徐裕键:业务高速增长过程中的团队迭代.md
- 099 徐裕键:业务高速增长过程中的技术演进.md
- 100 徐裕键:团队文化建设,保持创业公司的战斗力.md
- 101 刘俊强:领导力提升指南之培养积极的态度.md
- 102 姚从磊:巧用AARRR模型,吸引优秀技术人才(一).md
- 103 姚从磊:巧用AARRR模型,吸引优秀技术人才(二).md
- 104 姚从磊:巧用 AARRR 模型,吸引优秀技术人才(三).md
- 105 姚从磊:巧用 AARRR 模型,吸引优秀技术人才(四).md
- 106 程军:技术人的「知行合一」(一).md
- 107 刘俊强:消除压力的七种方法.md
- 108 谢呈:技术高手转身创业的坑和坡.md
- 109 谢呈:关于垂直互联网创业的一些经验之谈.md
- 110 成敏:创业公司为什么会技术文化产品缺失.md
- 111 蔡锐涛:从0到1再到100,创业不同阶段的技术管理思考.md
- 112 刘俊强:必知绩效管理知识之绩效管理循环.md
- 113 程军:技术人的「知行合一」(二).md
- 114 成敏:谈谈不同阶段技术公司的特点.md
- 115 成敏:打造优秀团队与文化的三个推手.md
- 116 刘俊强:必知绩效管理知识之绩效目标的制定.md
- 117 程军:技术人的「知行合一」(三).md
- 118 吴铭:成本评估是技术leader的关键素质.md
- 119 汤力嘉:CTO如何进行产品决策(一).md
- 120 刘俊强:必知绩效管理知识之绩效数据收集(上).md
- 121 刘俊强:必知绩效管理知识之绩效数据收集(下).md
- 122 黄伟坚:创业中那些永远回避不了的问题.md
- 123 黄伟坚:用系统性思维看待创业.md
- 124 刘俊强:必知绩效管理知识之评定绩效.md
- 125 洪强宁:从程序员到架构师,从架构师到CTO(一).md
- 126 洪强宁:从程序员到架构师,从架构师到CTO(二).md
- 127 刘俊强:必知绩效管理知识之绩效沟通(一).md
- 128 王坚:年轻人永远是创新的主体.md
- 129 刘俊强:必知绩效管理知识之绩效沟通(二).md
- 130 刘俊强:必知绩效管理知识之绩效沟通(三).md
- 131 汤力嘉:CTO如何在产品方面进行决策(二).md
- 132 徐函秋:转型技术管理者初期的三大挑战(一).md
- 133 徐函秋:转型技术管理者初期的三大挑战(二).md
- 134 刘建国:我各方面做得都很好,就是做不好向上沟通.md
- 135 钮博彦:软件研发度量体系建设(一).md
- 136 钮博彦:软件研发度量体系建设(二).md
- 137 成敏:创业者不要成为自己公司产品技术文化的破坏者.md
- 138 于艺:以生存为核心,B端产品的定位心法.md
- 139 成敏:创业者应该具备的认知与思维方式.md
- 140 袁店明:创业产品必须迈过的鸿沟.md
- 141 徐毅:五星级软件工程师的高效秘诀(一).md
- 142 徐毅:五星级软件工程师的高效秘诀(二).md
- 143 徐毅:技术Leader应该具备的能力或素质.md
- 144 于艺:如何提升自己的能力与动力.md
- 145 李列为:技术人员的商业思维.md
- 146 刘天胜:打造高效团队,关键在于平衡人、事和时间(一).md
- 147 刘天胜:打造高效团队,关键在于平衡人、事和时间(二).md
- 148 肖德时:创业团队技术领导者必备的十个领导力技能(上).md
- 149 肖德时:创业团队技术领导者必备的十个领导力技能(下).md
- 150 暨家愉:技术人如何快乐的自我成长(上).md
- 151 暨家愉:技术人如何快乐的自我成长(下).md
- 152 施翔:如何打造7 24高效交付通道(上).md
- 153 施翔:如何打造7 24高效交付通道(下).md
- 154 谢东升:说说技术管理者从外企到民企的挑战.md
- 155 王可光:如何搭建初创团队之人才关.md
- 156 成敏:技术人转型管理的两大秘诀.md
- 157 成敏:技术人才的管理公式.md
- 158 胡峰:人到中年:失业与恐惧.md
- 159 黄云:技术管理者如何科学的做好向上管理.md
- 160 胡键:创业公司需要高凝聚力高绩效的技术团队.md
- 161 卢亿雷:企业发展的不同阶段,该如何打造高效的研发流程体系.md
- 162 王海亮:提升技术团队效率的5个提示(上).md
- 163 王海亮:提升技术团队效率的5个提示(下).md
- 164 陈崇磐:心理成熟度 - 创业公司识人利器.md
- 165 陈崇磐:管事与管人 - 如何避开创业公司组队陷阱.md
- 166 俞圆圆:合格CTO应该做好的5件事(上).md
- 167 俞圆圆:合格CTO应该做好的5件事(下).md
- 168 余加林:从技术人到创业合伙人必备的三个维度的改变.md
- 169 高琦:如何给研发打绩效不头疼而又公正?(上).md
- 170 高琦:如何给研发打绩效不头疼而又公正?(下).md
- 171 邱良军:如何有效地找到你心仪的人才.md
- 172 于人:研发团队人均产能3年提升3.6倍的秘诀(上).md
- 173 于人:研发团队人均产能3年提升3.6倍的秘诀(下).md
- 174 邱良军:打造高效技术团队,你准备好了吗!.md
- 175 邱良军:打造高效技术团队的人才招聘攻略.md
- 176 胡键:创业公司如何打造高凝聚力高绩效的技术团队:组织篇.md
- 177 胡键:创业公司如何打造高凝聚力高绩效的技术团队:工具篇.md
- 178 马连浩:用人的关键在于用人所长,而非改人之短.md
- 179 张矗:技术管理者必经的几个思维转变.md
- 180 钟忻:成为温格-聊聊如何当好CTO.md
- 181 姚威:技术团队管理中关于公平的五个核心准则.md
- 182 谢文杰:区块链的下一个十年.md
- 183 薛文植:技术管理的本质-要做尊重人性的管理.md
- 184 狼叔:2019年前端和Node的未来-大前端篇(上).md
- 185 狼叔:2019年前端和Node的未来-大前端篇(下).md
- 186 赵晓光:如何培养团队竞争力(上).md
- 187 赵晓光:如何培养团队竞争力(下).md
- 188 张嵩:从心理学角度看待小中型团队的管理.md
- 189 狼叔:2019年前端和Node的未来-Node.js篇(上).md
- 190 狼叔:2019年前端和Node的未来-Node.js篇(下).md
- 191 肖冰:如何建立高信任度的团队.md
- 192 崔俊涛:如何做好技术团队的激励(上).md
- 193 崔俊涛:如何做好技术团队的激励(下).md
- 194 刘俊强:2019年云计算趋势对技术人员的影响.md
- 195 吴晖:企业B2B服务打磨的秘诀-ESI.md
- 196 邱良军:关于做好技术团队管理的几点思考.md
- 197 邱良军:做好研发管理的3个关键.md
- 198 徐林:通过快速反馈建立充满信任的技术团队.md
- 199 宝玉:怎样平衡软件质量与时间成本范围的关系?.md
- 200 邱良军:沟通,沟通,还是沟通(上).md
- 201 邱良军:沟通,沟通,还是沟通(下).md
- 202 陈嘉佳:奈飞文化宣言(上).md
- 203 陈嘉佳:奈飞文化宣言(下).md
- 204 邱良军:从小处着眼,修炼文化价值观.md
- 205 邵浩:人工智能新技术如何快速发现及落地(上).md
- 206 邵浩:人工智能新技术如何快速发现及落地(下).md
- 207 许良:科创板来了,我该怎么办?.md
- 208 陈阳:科创板投资,未来哪些行业受益最大?.md
- 大咖对话 万玉权:如何招到并培养核心人才.md
- 大咖对话 万玉权:高效团队的关键,以目标为导向,用数据来说话.md
- 大咖对话 不可替代的Java:生态与程序员是两道护城河.md
- 大咖对话 从几个工程师到2000多个工程师的技术团队成长秘诀.md
- 大咖对话 以产生价值判断工程师贡献--读者留言精选.md
- 大咖对话 余沛:打造以最佳交付实践为目标的技术导向.md
- 大咖对话 余沛:进阶CTO必备的素质与能力.md
- 大咖对话 刘俊强:云计算时代技术管理者的应对之道.md
- 大咖对话 刘俊强:谈谈我对2019年云计算趋势的看法.md
- 大咖对话 创业就是把自己过去的经验快速的产品化.md
- 大咖对话 如何打造自我驱动型的技术团队?.md
- 大咖对话 如何高效管理8000多规模的技术团队.md
- 大咖对话 季昕华:以不变的目的应对多变的技术浪潮.md
- 大咖对话 对人才的长期投资是人才体系打造的根本.md
- 大咖对话 张建锋:创业可以快而大,也可以小而美.md
- 大咖对话 彭跃辉:保持高效迭代的团队是如何炼成的.md
- 大咖对话 彭跃辉:解决用户痛点就是立足于市场的秘诀.md
- 大咖对话 徐毅:如何提升员工的活力与动力?.md
- 大咖对话 徐毅:打造高效研发团队的五个维度及相关实践.md
- 大咖对话 技术人创业前衡量自我的3P3C模型.md
- 大咖对话 技术人真正需要的是升维思考.md
- 大咖对话 技术管理者应该向优秀的体育教练学习.md
- 大咖对话 未来技术负责人与首席增长官将如何协作?.md
- 大咖对话 李昊:创业公司如何做好技术团队绩效考核?.md
- 大咖对话 李智慧:技术人如何应对互联网寒冬.md
- 大咖对话 杨育斌:技术领导者要打造技术团队的最大化价值.md
- 大咖对话 池建强:做产品不要执着于打造爆款.md
- 大咖对话 焦烈焱:从四个维度更好的激发团队创造力.md
- 大咖对话 玉攻:四个维度看小程序与App的区别.md
- 大咖对话 王坚:我从不吃后悔药.md
- 大咖对话 王平:从人、事、价值观、文化等维度看技术团队转型.md
- 大咖对话 王平:如何快速搭建核心技术团队.md
- 大咖对话 王鹏云:技术人创业该如何选择合伙人?.md
- 大咖对话 王鹏云:管理方式的差异是为了更好地实现企业商业价值.md
- 大咖对话 王龙:利用 C 端连接 B 端实现产业互联网是下半场的重中之重.md
- 大咖对话 童剑:用合伙人管理结构打造完美团队.md
- 大咖对话 管理者是首席铲屎官?.md
- 大咖对话 胡哲人:技术人创业要跨过的思维坎.md
- 大咖对话 袁店明:如何将打造自组织团队落诸实践.md
- 大咖对话 袁店明:打造高效研发团队的五个要点.md
- 大咖对话 让团队成员持续的enjoy.md
- 大咖对话 谢孟军:技术人如何建立自己的个人品牌.md
- 大咖对话 谭待:架构的本质是折中.md
- 大咖对话 陈天石:AI 芯片需要技术和资本的双重密集支撑.md
- 大咖对话 陈斌:如何打造高创造力、高动力的技术团队.md
- 大咖对话 陶真:技术人要爱上问问题,而不是自己的解决方案.md
- 大咖对话 韩军:CTO转型CEO如何转变思路.md
- 大咖对话 项目成功的秘诀--技术产品双头负责制.md
- 大咖对话 顾旻曼:投资时我们更多地是在找优秀的团队.md
- 大咖对话 高斌:过分渲染会过度拉高大众对人工智能的期望.md
- 大咖问答 发现下一个小米,不是只能靠运气.md
- 大咖问答 打造自己的个人品牌,你也可以.md
- 新春特辑1 卓越CTO必备的能力与素质.md
- 新春特辑2 如何成长为优秀的技术管理者?.md
- 新春特辑3 如何打造高质效的技术团队?.md
- 新春特辑4 如何打造高效的研发流程与文化?.md
- 新春特辑5 如何做好人才的选育用留?.md
- 温故而知新 一键直达,六大文章主题索引.md
- 结束篇 即使远隔千山万水,也要乘风与你同往.md
- 捐赠
055 用机器打造迭代机器:现代研发流程体系打造(二)
你好,我是爱范儿CTO兼知晓云负责人何世友,今天想跟大家继续聊聊“打造现代研发流程体系”这个话题,并将着重跟大家分享其中“用机器打造迭代机器”这一部分内容。
在上一篇文章里,我们分析了研发流程中的关键环节,并给出了对应的解法。它们分别是——
1.高速运转的传送带
现代化的项目管理(任务流转)工具。
2.可追溯的迭代
通过传送带,将每一次迭代的产物,如代码提交、架构设计变更、测试构建部署等串联并存储起来。
3.重要角色的沟通
用一个通用平台,如Slack,在解决人与人之间通讯的基础上,重点解决系统工具与人之间的沟通问题。
4.用机器打造迭代机器
受限于文章的篇幅,上篇文章中只是简单说到了因为迭代的步骤很多,所以要让机器包揽大部分环节,估计很多读者并不能十分感同身受。本文将对此做详细解释:为什么要用机器打造迭代机器?
迭代频率越高,对迭代里的自动化程度的要求就越高。打个简单的比方,如果项目要求一天迭代两次,测试工程师就要一天走完两次主流程回归测试。此时,人工就是最大的瓶颈。一个项目分分钟有成千上万个用例,依靠有限的测试人员分拣完成,那就是纯体力活了。而对质量的要求越高,主流程的覆盖范围就越广。单就这一个环节,如果没有机器的参与做自动化,就会成为一个不可调和的瓶颈了。
之前提到,构成自动化流程的大部分工具都是现成的、可以花合理价钱买到的,本文就将重点介绍研发流程里的各种工具们,以及不同场景下的具体选型。由于这些工具被正确配置完成之后,拥有脱离人工干预在不断电的情况下自我运转的能力,我们亲切地称之为迭代机器里的机器们。
迭代机器里的流水线
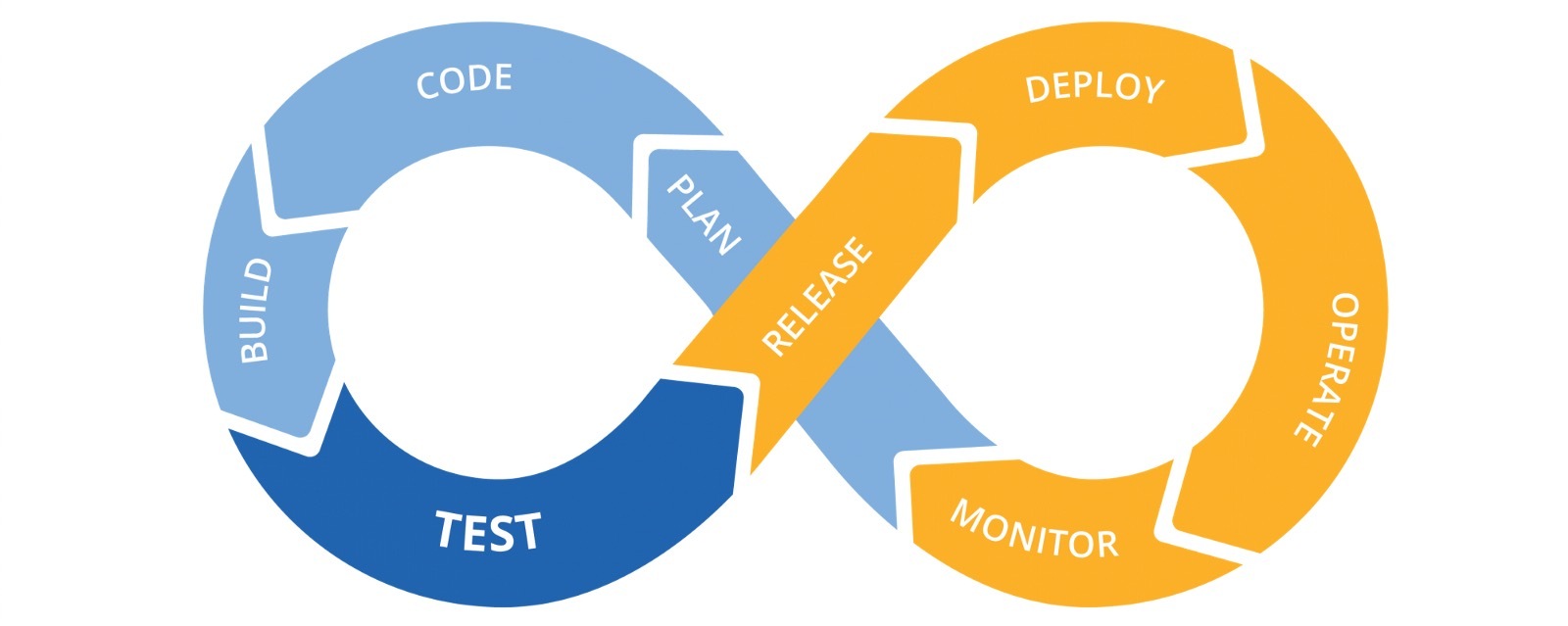
编码【人类才智】⟹代码审查【人类才智】⟹静态检查【机器】⟹单元测试【机器】⟹测试【机器】⟹构建【机器】⟹部署【机器】⟹监控【机器】⟹自动扩(缩)容【机器】。
这是一个环环相扣的流水线,每一个步骤都由一个机器角色完成并推送到下一个步骤,最终完成全程;一旦其中一环无法完成,则本次迭代就宣告失败,需要返工。
通常这样的流水线跑在 CI 系统上。CI 系统,Continuous Integration,持续集成系统。常见的 CI 有 Jenkins、Bamboo、Solano CI 等。这些系统各有千秋美丑,本文不赘述对比,各位可根据团队背景和成员喜好进行选择,只需要看这个系统是否具有真正意义上的可定制拓展性,以及规模可观的第三方服务的接入支持。
下边将围绕流水线中的几个重要环节进行描述。
静态检查、单元测试、构建
静态检查、单元测试和构建环节发生在每一次代码提交之后,由代码版本库的代码提交事件触发执行,如 Github、Bitbucket、Gitlab 的 Webhook 等。
1.静态检查
静态检查由各语言的语法 Lint 工具和bug 检查工具组成,前者包括 JS 的 eslint、Python 的 pylint 等,后者包括 Java 的 findbugs 等。
2.单元测试
基本上每种语言、每种框架都有支持单元测试,如 JS 的 Mocha、Python 的 unittest、Java 的 JUnit、Go 的 testing 等。工具本身都是比较类似的,各语言开发者都应该很熟悉。难在代码编写时的测试用例覆盖,这是一个需要仔细权衡覆盖度和时间的过程。
在实践中,比较推荐的是,让测试工程师参与到单元测试编写中来,每一次项目的测试用例评审,一部分用例一定要转化为开发工程师的单元测试。或者说,测试工程师需要参与到开发工程师的单元测试审查和覆盖率评估中,对应的,开发工程师也要参与到测试用例评审中。这二者相结合,黑白盒、单元集成测试才能真正有机的为项目质量负责。
3.构建
构建(Build)是需要开发工程师根据项目的部署策略编写对应的构建打包脚本。例如前端的 webpack、后端的 maven、客户端的打包等。不过基本上要做的事情就是将原本由工程师在本机上跑的脚本移植到 CI 系统上,这个过程本身不带来多少成本。
自动化测试
自动化测试由测试工程师维护,由两块工作构成:测试用例管理、自动化测试脚本编写。
1.测试用例管理
测试用例管理流行的工具有 Excel、Qmetry、TestLink 等。没错,Excel 在众多公司中依然是管理测试用例的好工具。当然在我们讨论的场景里,Excel 已经不堪其用。管理测试用例,是为了让测试用例和对应的需求描述,也就是 User Story 关联上。从而让每一轮测试执行,也就是 Test Run 的结果,不论是成功或失败,都自动回传到关联的任务状态里。
同时,平台级的用例管理,可以让用例迭代起来,和项目一起生长,这和前文提到的架构设计文档的迭代一脉相承。甚至,用例要作为项目推进中的自动化测试的组织枢纽,串联起自动化测试和实际任务的状态流转。
2.自动化测试
这里的自动化测试,主要指的是黑盒测试和集成测试,和开发工程师维护的单元测试做一个区分。常用的框架有 LoadRunner、Selenium、Appium 等。这是一个十分耗时耗力的过程,常见的做法是梳理经过每一次迭代的测试用例,最终形成一个主流程用例集。
主流程的特征是产品特性基本稳定,不会在短期内有较大改动。测试工程师需要对主流程的测试用例进行测试覆盖,例如通过 Selenium 进行 UIUE 的用户交互过程录制等。而有了主流程的覆盖,每次迭代的发布,才能够真正的做到 push on green。否则,每次发版还得测试人员手工回归确认,那基本就是一个跨不过去的时间鸿沟了。
部署、监控、自动扩(缩)容
1.部署
Devops 的兴起让运维得到解放,Docker 的流行也让社区疯狂,似乎非 Docker 不可,不上容器不是好技术团队。其实不见得。重要的是达到目的,而非工具,一定要根据项目实际情况进行技术选型,不要因为一种便利引入额外的麻烦。
目的是什么?目的是让机器自己完成自动化部署。
而通过前面介绍的工作,CI流水线上已经有了经过完整测试的构建产物,于是部署阶段只剩下:
- 开启并初始化机器,并完成系统环境配置,通常可以用预先准备好的镜像文件完成该步骤;
- 上传构建产物到机器上,启动服务;
- 将流量或任务分发到新的机器上;
- 下线旧的机器。
这里边有机器的运维、服务的部署、负载均衡器配置等,每一项业内都有非常不错的工具可以用。比如我们在爱范儿目前用的是——
- 使用 Ansible 完成环境的自动配置,结合AWS的ami镜像完成机器运维部分;
- 使用 Fabric 结合AWS的CodeDeploy完成的部署流程,并在此基础上完成了 Auto Scale。
AWS 的 CodeDeploy 非常好地利用了AWS的基础设施,可以一键完成上面提到的 1、2、3、4这几个环节。而在使用 CodeDeploy 之前,团队写了一系列脚本去做这块的工作。
Auto Scale 常见的做法是在监控系统里定义一系列的 Metrics,设定阈值,比如,“过去 2 分钟内机器 CPU 达到 60% 以上”就是一个完整的阈值条件定义。然后为这个阈值配置一个动作,比如“过去 2 分钟内机器 CPU 达到 60% 以上,部署并上线 4 台新的应用服务器”。而怎么部署并上线新机器就是上文的 CodeDeploy 的活儿了。
2.监控
监控分异常监控和性能监控。
异常监控配合日志收集器工作,如前端的 Sentry,后端的 Cloud Watch(AWS)、loggly等。基本的工作原理是从日志中获取错误信息,并进行统计,达到设定的阈值就开始报警。异常监控系统经常对接的是电话告警系统,为 OnCall 的工程师提供错误叫醒服务。
性能监控分微观和宏观两个维度:
- APM 探针实时收集应用服务器代码层面的性能信息;
- 机器状态(cpu、mem、load)、应用服务响应时间等。
这两者结合可以无死角反映服务状态,对接到 Auto Scale 系统后可以在大多数情况下完成自动化运维。
APM 探针服务,常用的有 NewRelic、AppDynamics 等,国内也有听云、OneAPM 等一众厂商。区别基本上就是价格和第三方支持完备度,近些年各大云服务商也在做这些周边支持,选择上并不是难事。也有一些团队将机器状态等信息归到异常监控里,而我们归到性能监控,主要是站在能否让机器自己治理的角度。毕竟,放到异常监控,OnCall 的工程师更容易醒,但醒了不也是要做 Scale 的事情嘛。
说到这里,大家在迭代流水线中的各个环节上都用了哪些工具呢?欢迎在留言中告诉我们,供大家参考。
一些待完成的和待思考的
然而,一台高速运转的迭代机器中,人类角色才是真正的瓶颈。或者说,高速迭代对人员的要求会更高。因此,团队的成长便更为重要,也更值得探讨。坊间有一句话,互联网公司都是轻资产,值钱的就是人、流程、代码。
那如何打造一个高速成长的团队呢?希望有机会可以和大家探讨。
作者简介
何世友,爱范儿CTO TGO鲲鹏会广州分会董事会成员,学习委员。从校园创业到跨国团队技术顾问再到如今,专注于高并发网络、机器学习、移动APP(部分硬件)、团队管理。
© 2019 - 2023 Liangliang Lee. Powered by gin and hexo-theme-book.